The Cost of Compute 2026
How 100 CFOs are approaching cloud costs in 2026.
Cloud Infrastructure Accounting Standards
GAAP-aligned principles for cloud and AI cost classification.
CFO Classification Handbook
A practical framework for classifying cloud and AI costs.
Practical guides for cloud-aware finance teams.


Report
The Cost of Compute 2026
What 100 CFOs revealed about cloud costs and how it impacts their P&Ls.
Get the reportThat question brought nearly 150 CFOs and finance leaders together for a live session I hosted with Ben Murray of The SaaS CFO. Rather than deliver another high-level warning about rising infrastructure costs, Ben and I got into the mechanics: how AI inference costs behave differently than traditional infrastructure, why the standard 80% gross margin assumption is under structural pressure, and what finance leaders can actually do about it.
The data we drew on comes from Cloud Capital's Cost of Compute 2026 report, which surveyed more than 100 growth-stage CFOs across the UK and US. A few findings shaped the conversation:
When gross margins compress from 80% to 30, 40, or 50%, the downstream math on LTV:CAC, payback period, and S&M investment capacity changes fundamentally. Running an AI-first business on a traditional SaaS operating model isn't just inefficient. It's a category error.
One of the most actionable parts of the conversation was on P&L classification. Not all cloud spend belongs in COGS, and getting this wrong has real consequences. Roughly 30 to 40% of a typical cloud bill is tied to development, testing, and model training rather than production workloads. Misclassifying that spend compresses reported gross margins without reflecting the underlying economics of the business.
AI makes this harder. A single Anthropic bill might include three economically distinct categories: production inference costs driven by customers using your product, dev and test inference used by your engineering team, and Claude Code usage for software development. Each belongs in a different place on your P&L. Separating them isn't just good accounting hygiene. It's the foundation for understanding your true unit economics.
The second half of our session covered the cost levers that finance and engineering teams can actually control. There are four worth knowing:

Ben closed on a point worth sitting with: CFOs don't need to become engineers, but they do need a working vocabulary around tokens, inference, and context windows. The finance teams getting the best outcomes are those who got into the data early, built shared language with their technical counterparts, and treated the AI pilot stage as the moment to establish cost discipline.
The Cost of Compute 2026 data backs this up. When finance and engineering jointly own cloud and AI infrastructure cost management, finance teams are more than twice as likely to produce highly predictable, accurate cloud spend forecasts, and nearly twice as likely to report high confidence in their COGS measurement. Shared ownership, more than any individual tool or process, is what drives that outcome.
Full transcript from the webinar "The Cost of AI: Cloud COGS, Margin Pressure, and the SaaS P&L," hosted by Ed Barrow (Cloud Capital) and Ben Murray (The SaaS CFO). Edited for brevity and clarity.
Ed Barrow: Welcome everyone. I'm Ed Barrow, founder and CEO of Cloud Capital, and I'm joined today by Ben Murray, The SaaS CFO. Ben has become something of a legend in the CFO community—I was told recently he's the Cristiano Ronaldo of CFOs, so we have an illustrious guest with us.
Today's session is designed to be interactive, so keep the chat open and drop your questions as we go. We'll be running polls throughout as well.
Here's what we're going to cover: how cloud has become an intrinsic part of the financial model for technology businesses; how AI is rapidly reshaping those costs and creating very different cost behaviors; how you can build predictability, visibility, and control into cloud and AI cost management; and how to structure ownership of these costs between finance and engineering.
What's backing this session is a survey of over 100 growth-stage CFOs and finance leaders across the UK and the US, which we ran at the end of last year. The full results are available in Cloud Capital's Cost of Compute 2026 report at cloudcapital.co/the-cost-of-compute. We'll be pulling out highlights throughout today, but the full data set is there if you want to dig in further.
Ben Murray: Great to be here. This is a topic that's near and dear to every CFO and controller right now. Looking forward to it.
Ed: The most important shift to understand is that cloud has fundamentally transformed its role in the cost structure of software businesses. Cloud is now the largest variable cost line for most technology companies, and typically the second largest cost line overall, after headcount.
I was speaking with an AI-native startup this morning who announced that their cloud and infrastructure costs have now eclipsed their payroll. It's their single largest line item. That's an extreme case today, but it's becoming less extreme quickly. For most companies, cloud has risen to that second position and it is highly variable and often opaque in terms of what you're actually spending and how it's likely to change.
AI has accelerated all of this significantly. What was a rapidly growing cost base has become something larger and more urgent, with a material impact on the fundamental unit economics of software businesses.
Ben: That's a big point. I've written about SaaS math versus AI math, and the transition between the two is not trivial. If your margin profile shifts materially, you almost have to operate your business differently—how you think about OPEX, how you think about different unit costs. It changes a lot downstream.
Ed: Most of us have built software businesses on a well-established playbook: target 80% gross margin, and from there you have a predictable framework for how much to invest in sales and marketing and R&D. That playbook is being undermined.
When you're talking about gross margin compressing from 80% down to 30, 40, or 50%, the impact isn't just a larger cost line. When you think about LTV to CAC, payback period, and investment decisions, all of those should be assessed on a gross profit basis. If you're generating materially less gross profit per dollar of revenue, you need to think much more carefully about how you invest in customer acquisition and customer management. It's a fundamentally different business model to operate.
There's an interesting dynamic here. A lot of AI-native businesses are looking at their plans and saying, we don't think we need to scale headcount as quickly because we're an AI-native business. But it may actually work the other way: you can't afford to scale headcount as quickly because you're spending so much on cloud and infrastructure.
Ben: Any AI-native founder or CFO really has to understand this. The unit economics are thinner, the margin profile is different, and unless you have significant capital to burn through, you have to operate accordingly. AI-first businesses are still shooting for 70–80% gross margin eventually, but getting there requires a plan and real cost discipline along the way. The path matters as much as the destination.
Ed: The first question we always get asked is: I'm spending X on cloud and infrastructure. Is that reasonable? Am I over-invested or under-invested relative to my peers?
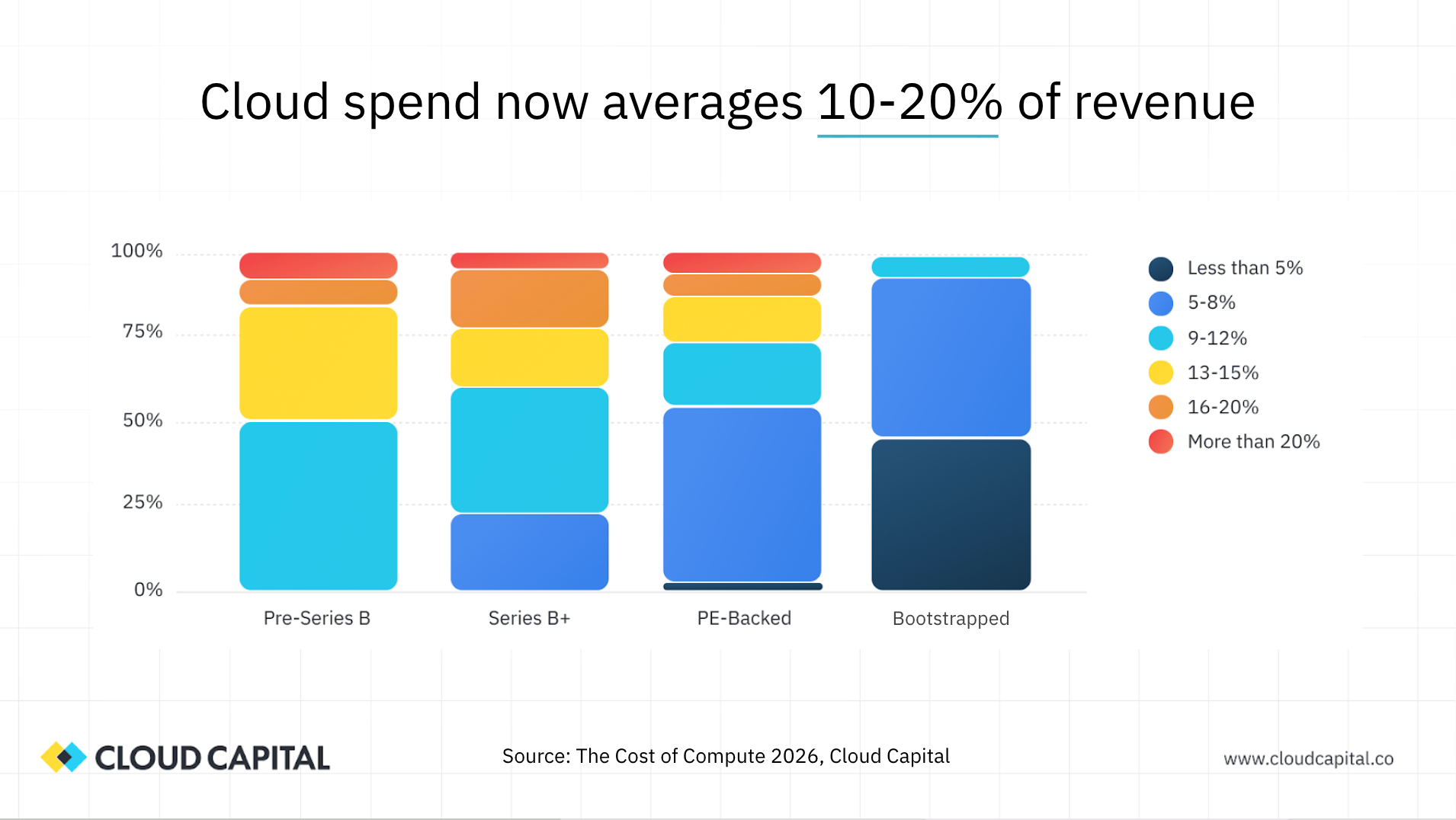
The survey data shows that most organizations are spending somewhere between 10 and 20% of revenue on cloud. As you'd expect, earlier-stage businesses tend to spend a higher percentage of revenue, and that ratio improves as companies scale. Businesses that are more profitability-focused tend to run leaner. But even so, there are quite a few companies sitting at 16 to 20% or above, which is a very material line item. This is no longer a cost that sits quietly in the background.
Ben: When I look at that data, the benchmark that rings true for a well-run, PBAC-oriented SaaS business is around 5 to 8% of revenue for cloud and infrastructure. If you think about hitting 80% gross margin and your COGS bucket includes hosting and infrastructure alongside tech support, professional services, and customer success, 5 to 8% is about right for the infrastructure portion. If it's climbing above 10%, that's a signal worth investigating regardless of your growth stage.
Ed: The direction of travel is the more concerning finding. Eighty percent of CFOs in our survey reported that cloud spend is increasing as a percentage of revenue. That's the opposite of what you'd hope for. As businesses grow, you'd expect infrastructure spend to scale sub-linearly—you should be gaining efficiency. Instead, most organizations are seeing that percentage grow, with the majority reporting increases of two to five percentage points over the past 12 months.
That's a material change in the cost base over a short period, and it's flowing directly into gross margin. And the cause is not surprising: AI is the primary driver. For traditional SaaS businesses that are adding AI capabilities to their products, AI now represents 22% of total cloud spend, up from essentially zero 18 months ago.
Ben: Wall Street analysts are asking the same questions of public tech companies on earnings calls: how does adding AI inference change your cost structure, and can you charge more to offset it? Those are the two fundamental questions. They're also the right questions for every SaaS CFO to be asking internally.
Ed: Before we can talk about how to manage AI costs, it helps to be clear about what we actually mean when we say "AI spend," because it's not a single thing. There are three distinct categories.
The first is model training. This is the process of developing or fine-tuning a model—renting or purchasing GPUs and using them to build the foundation of your AI capabilities. This was the primary AI cost story in 2024 and into 2025. It's resource-intensive, capital-intensive, and not something most software companies need to do themselves.
The second is inference. This is where most SaaS companies are today. Inference means using a model in production as part of your product—querying a model and returning results to your customers. That model might be one you trained yourself, but more commonly it's an off-the-shelf model from a provider like Anthropic, OpenAI, or Google Gemini. Inference costs are driven by your customers using your product, which makes them production costs that belong in COGS.
The third category, which is easy to overlook, is the knock-on effect on underlying infrastructure. Embedding AI into your product requires substantially more data: gathering it, storing it, processing it, passing it to the model, receiving results, and presenting them to customers. Businesses that were data-light a few years ago are now data-intensive by necessity. The AI bill from Anthropic is often accompanied by a quietly growing AWS or Google Cloud bill driven by compute, storage, and data transfer associated with AI workloads.
Ben: A good example from a founder I interviewed: a legal tech company building contract analysis tools can't just run a generic OpenAI prompt. They need to feed context, domain knowledge, and customer-specific data into the model to make it genuinely useful. That combination of training and enriched inference is what makes the product work—and it's also what makes the cost structure complex.
Ed: Let's talk about where these costs actually belong on the P&L, starting with training. Model training typically happens in one of two places: either within your existing cloud provider—renting GPUs from AWS or Google by the hour, similar to how you rent compute—or through specialist GPU cloud providers like CoreWeave or Nebius, which often have pricing or availability advantages for training workloads.
The critical accounting point is this: model training costs should not be in your COGS. This is a capital investment in a new capability. If you include the full cost of GPU hours for model training in your gross margin calculation, you can dramatically misrepresent the economics of your business. The cost needs to be clearly separated and classified under R&D or OPEX.
We've worked with early-stage companies spending north of 50% of revenue on model training. If that's going into COGS, the reported gross margin becomes nearly meaningless. And once you've trained a model, you also need to account for the cost of retraining and updating it over time—this is not a one-time investment.
Ben: From a GAAP or IFRS perspective, it's also worth asking whether any of these development costs should be capitalized alongside other product development work. If you're building a new AI-driven product capability, the model training costs that meet the capitalization criteria could be treated as a capital asset rather than a period expense. That's a conversation worth having with your auditors.
Ed: Most SaaS companies today are focused on inference rather than training. They're choosing an existing model and embedding it into their product. There are a few different ways to access these models, and the choice has both cost and architectural implications.
The original approach was direct API access: go to Anthropic or OpenAI, get API credentials, query the model from your code, and receive the bill at the end of the month. That's still a common path.
The alternative, which is growing in popularity, is using an inference platform hosted by your cloud provider. AWS has Bedrock, Google has Vertex AI and AI Studio, and Microsoft has AI Foundry. These platforms host a range of models—including both proprietary models like those from Anthropic and open-source models—and abstract away the infrastructure management. For companies already running on AWS, accessing models through Bedrock can make sense from a latency, data transfer, and data security perspective.
Now, here's the P&L classification point that matters: inference costs are not all the same. A single bill from Anthropic—or from AWS Bedrock—can contain at least three economically distinct categories of spend, and each belongs in a different place on your P&L.
The first is production inference: your customers are using your product, the product is calling the model, and those costs are driven by customer usage. That's COGS.
The second is development and test inference: your engineering team is building and testing new AI features, querying the model as part of that work. Those costs are not yet serving customers. That's OPEX, not COGS.
The third is tooling: if your engineers are using Claude Code to write the software itself, that cost also appears on your Anthropic bill but has nothing to do with production workloads. It needs to be separated out.
Many organizations are taking their entire cloud vendor bill and routing it straight into COGS. That's overstating your cost of goods sold and understating your gross margin. The discipline of separating these categories is not just good accounting hygiene—it's the foundation for understanding your true unit economics.
Ben: This is exactly what I did during close as a CFO: split the bill. What's going to sales as demo environments? What's going to dev and test? You have to do that work, and with AI costs it becomes more complex and more important. If your DevOps and infrastructure bucket—including all third-party software embedded in your product—rises above 10% of revenue, that's a flag. Understanding which portion of that is production versus development spend is essential to knowing what the number actually means.
Ed: It's easy to focus entirely on the Anthropic or OpenAI line item and miss the downstream infrastructure impact. When you embed AI into your product, you're almost certainly driving increased spend on your core cloud provider as well—on compute, storage, and data transfer.
The reason is straightforward: to get good results from a model, you need to give it context. The more data you've gathered on a customer over time—their interaction history, their preferences, their data—the more you can feed to the model and the better the output. That data has to be stored, processed, and passed to the model on every query.
I was working with an AI-native company recently that was thinking very carefully about context window size—how much data they pass to the model on each call. They hadn't constrained this initially, and the models were returning very verbose responses. Both the input and output data volumes were driving infrastructure costs they hadn't anticipated.
There's also a lifecycle dynamic worth flagging: early customers are cheap to serve because you don't have much data on them yet. As customers mature and their data accumulates, the cost to serve them increases. If your growth slows, the proportion of your customer base in that more expensive mature stage grows, and your gross margin deteriorates—even without any change in pricing or usage patterns. Understanding that dynamic early is important.
Ben: That context window point is something I've experienced firsthand building my own applications. You're asking yourself: am I passing gigabytes or megabytes to the model for each query? It's a real cost driver and not always visible until you're looking at the token-level data.
Ed: Once you understand the cost categories and where they belong on the P&L, the next question is: what can you actually do about them? There are four primary levers.
Usage intensity is the first. How broadly have you embedded AI across your product, and does that depth match the value you're delivering to each customer cohort? It's tempting to embed AI as deeply and pervasively as possible—and there's real commercial pressure to do so. But calling a model on every user interaction, including low-value ones, drives costs without a corresponding margin return. The discipline is asking: which parts of the product genuinely benefit from AI, and for which customer cohorts? Not every task needs the full model.
Model selection is the second. Anthropic alone has a range of models from Opus at the high end to Haiku at the low end, with radically different cost profiles. The most capable model is not always the right model for every task. Engineering teams are increasingly building tiered model architectures: a more capable model handles orchestration and planning, while cheaper models handle specific execution tasks where the quality difference is negligible. Moving 40% of your model interactions to a cheaper tier can have a meaningful impact on gross margin even with the same usage volume.
Token volume is the third. Every token you send to a model and every token you receive back has a cost. Long prompts, large context windows, and verbose output all drive token spend. Being deliberate about how much data you pass to the model, and asking for concise rather than expansive outputs, has a direct and measurable effect on cost per interaction.
Architectural design is the fourth. Caching, batching, and retry logic are engineering-level decisions with real financial implications. If the same query has been made before, caching the response avoids calling the model again. Batch processing is often significantly cheaper than real-time processing for tasks that don't require instant responses. Retry behavior on failed calls, if unmanaged, can generate substantial unnecessary cost. These are low-level decisions that need to be part of the design conversation from the start, not addressed after costs have already scaled.
Ben: This slide is worth screenshotting for anyone following along—these four levers are the framework for the conversation between finance and engineering on AI costs. It is a bit of a black box for most CFOs today, just as cloud hosting costs were a few years ago. Having this framework gives you a vocabulary to engage with your technical team.
Ed: The math that connects these levers to your P&L follows a straightforward chain. Cost per token, multiplied by the tokens consumed per interaction, gives you cost per interaction. Cost per interaction, multiplied by the number of interactions per user, gives you cost per user. Cost per user, set against the revenue you're generating per user, gives you your gross margin impact.
That bottom-up view—starting from the token level—is how you build a credible model of your AI unit economics. It's also how you build a forecast: if you can estimate usage patterns and model the impact of architectural improvements, you can project how your margins will evolve as the product scales.
The translation challenge is that the inputs to this model live on the engineering side. Finance teams are used to working from the monthly cloud vendor bill. Engineers are working at the level of tokens per request, cache hit rates, and model call frequency. Bridging those two views is the core work of building a shared financial model for AI costs.
Ben: For CFOs in the audience—I've learned a lot from building my own AI applications on tools like Replit. Looking at actual token usage data for a given query type, understanding the difference between input and output token costs, and calculating cost per interaction firsthand is genuinely illuminating. If you have the opportunity to get into that data with your CTO, do it. It changes how you think about the numbers on the vendor bill.
Ed: With traditional cloud spend, the typical pattern was: engineering made infrastructure decisions early, costs were relatively opaque, and finance only got involved once the bill reached tens or hundreds of thousands of dollars a month. By that point, the architectural decisions that drove those costs were long since made.
AI can't follow that pattern. The cost intensity of AI workloads, and the sensitivity of those costs to architectural decisions, means that finance needs to be in the room at the pilot stage—not the scale stage.
We have customers spending hundreds of thousands a month on overall cloud who are currently laser-focused on the $5,000 they spent on Anthropic in a small closed beta. That's exactly the right instinct. At that pilot stage, you're establishing the unit economics: how many customers were in the beta, how many interactions did they have, what was the cost per interaction? That analysis, done early, shapes every architectural and investment decision that follows.
The practical framework most finance leaders in our survey gravitated toward is a structured pilot with defined cost guardrails: a limited beta group, a spending cap, a clear set of unit economics metrics to track, and a joint review cadence between finance and engineering. The goal is to understand the economics before they scale, not after.
The shared vocabulary piece is also non-negotiable. Finance needs to understand what tokens, context windows, caching, and batch processing mean. Engineering needs to understand what gross margin, unit economics, and COGS classification mean. The teams that develop that shared language early are the ones with clear visibility into what's happening and why.
Ben: That's the translation exercise. Finance is used to receiving a 70-page PDF from AWS at the end of the month that's largely indecipherable at the line item level. Engineering is working at the level of tokens per request and cache hit rates. Building the bridge between those two views—having the conversation that connects engineering decisions to margin outcomes—is where the value is. And it has to start early.
Ed: We asked CFOs in our survey about the outcomes they were seeing based on how they were managing cloud and AI costs: how predictable was their spend, how confident were they in their COGS measurement, how much visibility did they have into what was driving costs, and how mature were their cost optimization practices.
The pattern was clear. If engineering is managing this alone, predictability and confidence in COGS are low. If finance is managing it alone, the situation improves but is still limited. When finance and engineering own it jointly, the outcomes are substantially better. Finance teams operating with that joint ownership model are more than twice as likely to produce highly predictable, accurate cloud spend forecasts, and nearly twice as likely to report high confidence in their COGS measurement. Shared ownership, more than any individual tool or process, is what drives that outcome.
Ed: Everything we've discussed today is grounded in Cloud Capital's Cost of Compute 2026 report, which surveyed over 100 CFOs and is available at cloudcapital.co/the-cost-of-compute. If you want the full data set and benchmarks, that's where to go.
If your immediate challenge is that your cloud bill is simply larger than it should be and you need to get it back under control before you can think about AI unit economics, we've launched a cash back program that returns 5% on your entire cloud bill immediately, without requiring your engineering team to make changes or spend months explaining the bill. That's at cloudcapital.co/cashback.
Ben: There were a lot of requests for slides during the session—those will be shared. And Ed, I know you plan to keep updating the benchmarking data on cloud costs over time, which is something every CFO will want to follow as this environment continues to evolve. I'm at ben@thesaascfo.com if anyone has questions for me. This was a great session—a lot of genuinely useful frameworks in here for your teams.
Ed: Thanks Ben, and thanks to everyone who joined us. This is a topic where finance and engineering are going to have to collaborate more closely than they ever have, and there's real value in doing so. We'll continue working with CFOs across the industry to track how this environment changes. As we all know, it's changing very quickly.

Report
Download The Cost of Compute 2026
Cloud Capital earns a share of the savings we generate for you. If you don't save, we don't get paid. Our incentives are fully aligned with yours. Ready to take control of your cloud spend?


